 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIN-Bench: Tracing Native Evidence Chains in Long-Context Multimodal Scientific Interleaved Literature
Jan 15, 2026Evaluating whether multimodal large language models truly understand long-form scientific papers remains challenging: answer-only metrics and synthetic "Needle-In-A-Haystack" tests often reward answer matching without requiring a causal, evidence-linked reasoning trace in the document. We propose the "Fish-in-the-Ocean" (FITO) paradigm, which requires models to construct explicit cross-modal evidence chains within native scientific documents. To operationalize FITO, we build SIN-Data, a scientific interleaved corpus that preserves the native interleaving of text and figures. On top of it, we construct SIN-Bench with four progressive tasks covering evidence discovery (SIN-Find), hypothesis verification (SIN-Verify), grounded QA (SIN-QA), and evidence-anchored synthesis (SIN-Summary). We further introduce "No Evidence, No Score", scoring predictions when grounded to verifiable anchors and diagnosing evidence quality via matching, relevance, and logic. Experiments on eight MLLMs show that grounding is the primary bottleneck: Gemini-3-pro achieves the best average overall score (0.573), while GPT-5 attains the highest SIN-QA answer accuracy (0.767) but underperforms on evidence-aligned overall scores, exposing a gap between correctness and traceable support.
Physical Knowledge Enhanced Deep Neural Network for Sea Surface Temperature Prediction
Apr 19, 2023



Traditionally, numerical models have been deployed in oceanography studies to simulate ocean dynamics by representing physical equations. However, many factors pertaining to ocean dynamics seem to be ill-defined. We argue that transferring physical knowledge from observed data could further improve the accuracy of numerical models when predicting Sea Surface Temperature (SST). Recently, the advances in earth observation technologies have yielded a monumental growth of data. Consequently, it is imperative to explore ways in which to improve and supplement numerical models utilizing the ever-increasing amounts of historical observational data. To this end, we introduce a method for SST prediction that transfers physical knowledge from historical observations to numerical models. Specifically, we use a combination of an encoder and a generative adversarial network (GAN) to capture physical knowledge from the observed data. The numerical model data is then fed into the pre-trained model to generate physics-enhanced data, which can then be used for SST prediction. Experimental results demonstrate that the proposed method considerably enhances SST prediction performance when compared to several state-of-the-art baselines.
Physics-Guided Generative Adversarial Networks for Sea Subsurface Temperature Prediction
Nov 04, 2021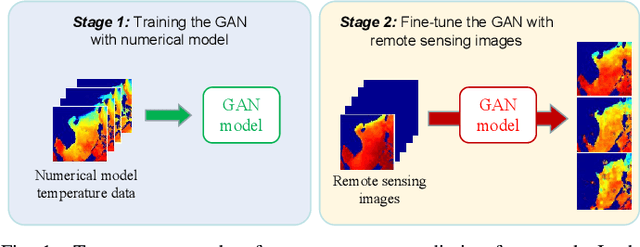
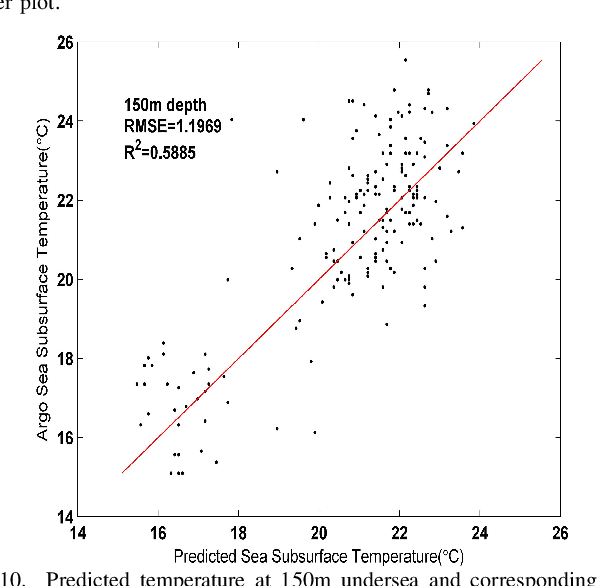
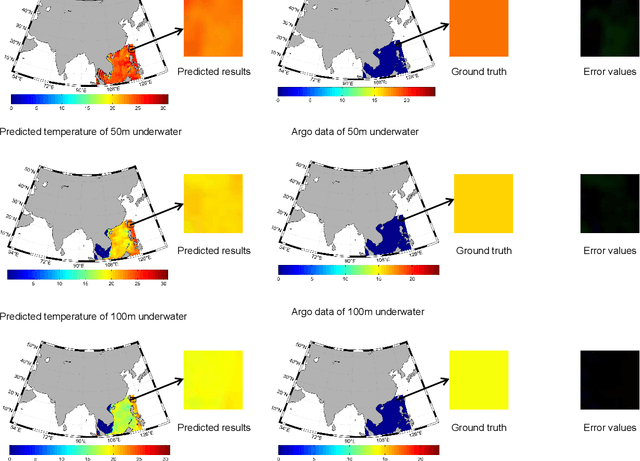
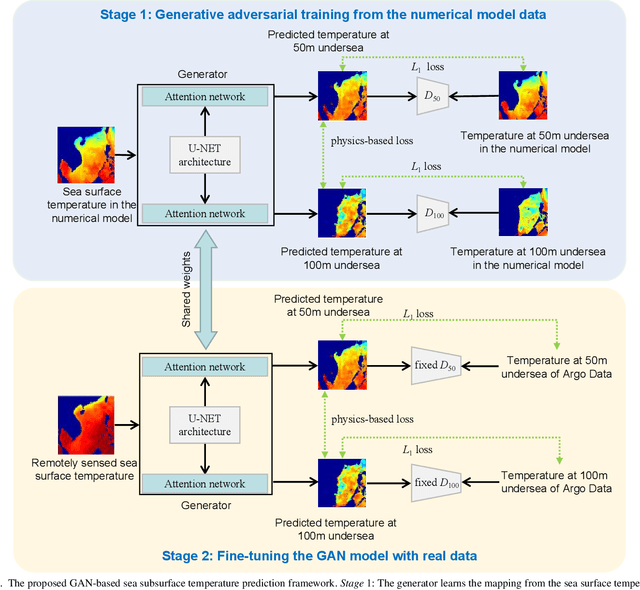
Sea subsurface temperature, an essential component of aquatic wildlife, underwater dynamics and heat transfer with the sea surface, is affected by global warming in climate change. Existing research is commonly based on either physics-based numerical models or data based models. Physical modeling and machine learning are traditionally considered as two unrelated fields for the sea subsurface temperature prediction task, with very different scientific paradigms (physics-driven and data-driven). However, we believe both methods are complementary to each other. Physical modeling methods can offer the potential for extrapolation beyond observational conditions, while data-driven methods are flexible in adapting to data and are capable of detecting unexpected patterns. The combination of both approaches is very attractive and offers potential performance improvement. In this paper, we propose a novel framework based on generative adversarial network (GAN) combined with numerical model to predict sea subsurface temperature. First, a GAN-based model is used to learn the simplified physics between the surface temperature and the target subsurface temperature in numerical model. Then, observation data are used to calibrate the GAN-based model parameters to obtain better prediction. We evaluate the proposed framework by predicting daily sea subsurface temperature in the South China sea. Extensive experiments demonstrate the effectiveness of the proposed framework compared to existing state-of-the-art methods.